TSG 部報 第 200 号・夏休み号
文字コードの話(第2回)
早坂くりす
第4章 ISO 2022
この章では、ISO 2022という規格について解説します。この規格は、複数の文字集合を組み合わせ、切り換えて使うための枠組みを規定したもので、文字コード体系を理解する上でぜひ知っておく必要のある重要な規格です。
なお、ISO 2022はJIS X 0202というJIS規格にもなっています。
4.1 ISO 2022の考え方
文字コードは一般に7ビットまたは8ビットのバイト列で構成されます。一方、表現すべき文字のほうは、欧米でも数百字、漢字文化圏では数千〜数万字に達します。しかも使われる文字は言語や国によって大きく異なるため、各国がそれぞれに文字集合を規格化しています。すなわち、コード空間の狭さに比べて文字種ははるかに多く、かつ多数の文字集合が存在しています。
このような状況で、さまざまな文字データを支障なく表現・交換するためには、各国の文字集合の規格を組み合わせ、また切り換えて使うことが考えられます。すなわち、普段必要とする文字を含む文字集合を組み合わせて運用し、それ以外の文字が必要となったときはそれを含む文字集合に動的に切り換えます。この枠組みを規定したのがISO 2022です。一方、これに対して、コード空間を大きくとり、その中にあらゆる文字を含めるという方法も考えられます。これを実現したのがISO 10646/Unicodeです。
4.2 7単位系の指示と呼び出し
それでは、いよいよISO 2022の具体的な解説に入っていきましょう。
まずは7単位系(7ビット符号)から解説します。7ビットの符号空間は0x00〜0x7Fの範囲がありますが、この空間をインユーステーブル(in-use table)といいます。
7単位系のインユーステーブルは2つの領域に分けられます。一つは制御文字を割り当てる領域で、C0領域といい、0x00〜0x1Fです。残りの0x20〜0x7Fは、図形文字を割り当てる領域で、GL領域といいます。このそれぞれの領域にどの文字集合を割り当てるかが決まれば、各々の符号の表現する文字もめでたく決まるわけです。
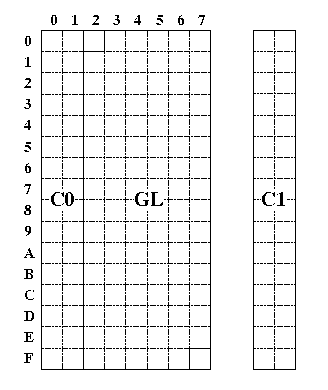
ISO 2022 のインユーステーブル(7単位系)
文字集合の割り当ての機構は、制御文字と図形文字で異なっています。
制御文字の場合は、単に、所定のエスケープシーケンスによって、C0領域にどの制御文字集合を割り当てるかを決定します。これに対して、図形文字集合の割り当ては二段構えになっています。インユーステーブルの他に、G0〜G3という4個の中間バッファが設けてあり、図形文字集合をいずれかの中間バッファに割り当て、それからいずれかの中間バッファをGL領域に割り当てるという機構になっています。図形文字集合を中間バッファに割り当てることを「指示する(to designate)」といい、中間バッファをGL領域に割り当てることを「呼び出す(to invoke)」といいます。指示はエスケープシーケンスによって、また呼び出しは制御文字によって行われます。
このような複雑な機構になっている理由は後ほど考えることにしますが、この指示/呼び出しの機構がISO 2022の中核となる部分ですので、よく理解しておいてください。インユーステーブル・中間バッファ・図形文字集合という階層構造のモデルは、コンピューターの記憶装置におけるレジスタ・主記憶・外部記憶といった階層構造になぞらえることもできます。
なお、指示と呼び出しは独立の機能ですので、指示した後すぐに呼び出さなくてはならないということはありません。また、すでにインユーステーブルに呼び出されている中間バッファに対して図形文字集合を指示すると、改めて呼び出しをしなおさなくても、即座に指示がインユーステーブルに反映されることになっています。
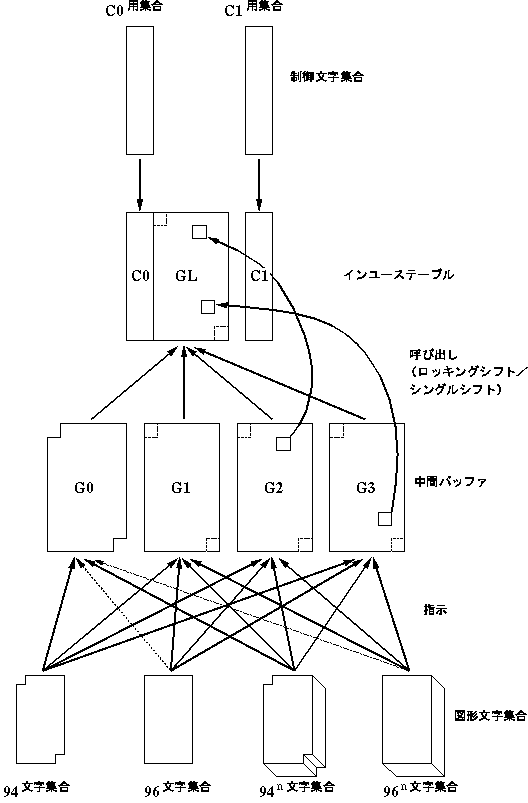
ISO 2022 の構造(7単位系)
4.3 ISO 2022で使える文字集合
ここでは、ISO 2022で使える文字集合について説明します。ISO 2022はどんな文字集合でも使えるわけではなく、上述のインユーステーブルの構造と一致する文字集合でなければなりません。制御文字については、C0領域が0x00〜0x1Fの32文字なので、32文字の制御文字集合を用いることができます。図形文字は、GL領域が0x20〜0x7Fの96文字なので、96文字の図形文字集合を用いることができます。
ただし実際には、ASCII/ISO 646との互換性のために、GL領域を0x21〜0x7Eの94文字に制限して、0x20は空白文字、0x7Fは制御文字DEL(削除)として使われるのが普通です。この場合、94文字の図形文字集合を用いることができます。94文字集合をGL領域に呼び出すと、自動的に0x20は空白文字、0x7FはDELになります。
94文字図形文字集合の例としては、ASCII図形文字、ISO 646図形文字(JIS X 0201ローマ文字を含む)、JIS X 0201カタカナなどがあります。96文字図形文字集合の例としては、ISO 8859の右半分などがあります。
漢字のような文字数の多い図形文字は、94文字/96文字集合では収容できませんので、複数バイト文字集合として規定されます。すなわち、
2バイト符号の場合は、94×94文字または96×96文字
3バイト符号の場合は、94×94×94文字または96×96×96文字
となります。例えば、JIS X 0208は94×94文字図形文字集合であり、1区1点から94区94点までの8836個の符号空間を持ちます。ちなみに、古いISO 2022では、複数バイト文字集合はG0にのみ指示できることになっていましたが、現在ではこの制限はありません。
なお、96文字集合や96n文字集合をG0に指示することはできないことになっています。G0はGLに呼び出されるべきデフォルトのバッファであると考えられるため、ここに96文字集合が指示されていると、0x20が空白でなくなるなど問題が多いからかもしれません(GLに96文字集合を呼び出すこと自体は、G1〜G3を使えば可能です)。
4.4 呼び出し:ロッキングシフトとシングルシフト
上述のように、図形文字集合用の中間バッファG0〜G3をGL領域に割り当てることを「呼び出す」といいますが、これには2通りの方法があります。一つはロッキングシフトといい、いったん割り当てたら次に割り当て直すまでずっと有効となるものです。もう一つはシングルシフトといい、1文字分だけ臨時に呼び出しを変更するものです。呼び出しのパターンと、それを実現する制御文字の名称を以下に示します。
| 呼び出しの方法 | 呼び出しの内容 | 制御文字 |
|
ロッキングシフト | G0→GL | SI (Shift In) |
|---|
| G1→GL | SO (Shift Out) |
| G2→GL | LS2 (Locking Shift 2) |
| G3→GL | LS3 (Locking Shift 3) |
|
シングルシフト | G2→GL | SS2 (Single Shift 2) |
|---|
| G3→GL | SS3 (Single Shift 3) |
G0/G1のロッキングシフトはLS0/LS1でなくSI/SOという名称になっています。また、シングルシフトはG2/G3にしかありません。
シングルシフトの制御文字SS2(SS3)が現れたら、それに続く1文字分の符号を、G2(G3)に指示されている図形文字集合の符号として解釈します。すなわち、後続の1文字分の符号に限って臨時に呼び出しを変更することに相当します。なお、「1文字分の符号」のバイト数は、G2(G3)に指示されている図形文字集合によって決まります。必ずしも1バイトとは限りません。
4.5 8単位系の指示と呼び出し
ISO 2022では8単位系(8ビット符号)についても規定されています。8単位系のインユーステーブルの構造は、7単位系との互換のために、7単位系のそれを二つ組み合わせたような形になっています。
| C0領域 | 0x00〜0x1F | 制御文字の領域 |
|---|
| GL領域 | 0x20〜0x7F | 図形文字の領域 |
|---|
| C1領域 | 0x80〜0x9F | 制御文字の領域 |
|---|
| GR領域 | 0xA0〜0xFF | 図形文字の領域 |
|---|
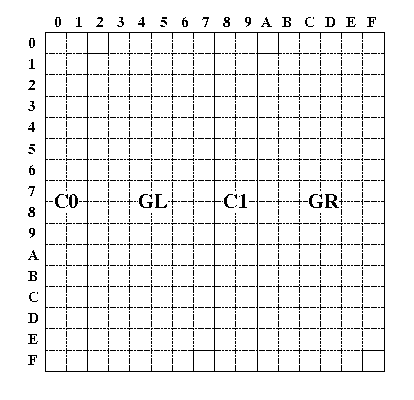
ISO 2022 のインユーステーブル(8単位系)
指示および呼び出しの機構は基本的に7単位系と同じです。
制御文字の領域はC0/C1の2つありますが、制御文字集合はそれぞれC0用またはC1用のいずれかと決められており、C0用制御文字集合をC1に割り当てることやその逆はできません。図形文字はそのような制限はなく、基本的には自由に指示し呼び出すことができます(ただし、7単位系のところで述べたように、いくつか例外的な制約があります)。
中間バッファG0〜G3は7単位系と同じですが、インユーステーブルにGR領域が追加されたことに伴い、呼び出しの機能が追加・変更されています。
| 呼び出しの方法 | 呼び出しの内容 | 制御文字 |
|
ロッキングシフト(左) | G0→GL | LS0 (Locking Shift 0) |
|---|
| G1→GL | LS1 (Locking Shift 1) |
| G2→GL | LS2 (Locking Shift 2) |
| G3→GL | LS3 (Locking Shift 3) |
|
ロッキングシフト(右) | G1→GR | LS1R (Locking Shift 1 Right) |
|---|
| G2→GR | LS2R (Locking Shift 2 Right) |
| G3→GR | LS3R (Locking Shift 3 Right) |
|
シングルシフト | G2→GL/GR | SS2 (Single Shift 2) |
|---|
| G3→GL/GR | SS3 (Single Shift 3) |
7単位系と大きく異なるのは、GRへの呼び出しを行うLS?Rが追加されたことです(ただし、G0をGRに呼び出すことはできないことになっています)。また、7単位系のSI/SOがLS0/LS1とわかりやすい名前に改められました。シングルシフトはGLに呼び出すのが原則ですが、GRに呼び出してもよい(シングルシフトに続く符号のMSBが1でもよい)ことになっています。
複数バイト図形文字集合もGRまたはGLのいずれか一方に呼び出されますので、2バイト文字の第1バイトをGRに割り当てて第2バイトをGLに割り当てるといったようなことはできません。7単位系との連続性を優先した結果ですが、符号空間の有効利用という観点からは不満の残るところです。
なお、94文字集合や94n文字集合をGLに呼び出した場合は、0x20が空白で0x7FがDELになりますが、GRに呼び出した場合は、0xA0と0xFFは使用禁止となります。
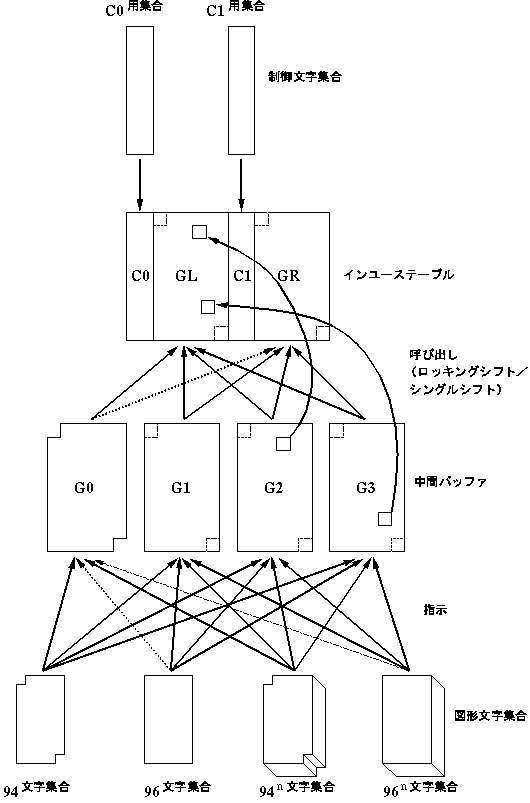
ISO 2022 の構造(8単位系)
4.6 ISO 2022の制御機能
これまでみてきたように、ISO 2022では指示や呼び出し(ロッキングシフト、シングルシフト)といった制御機能をもっていますが、これは実際には制御文字やエスケープシーケンスを用いて表現されます。制御文字はC0制御文字とC1制御文字があります。また、C0制御文字のESC(0x1B)に続いて0x20〜0x7Eの範囲の符号を並べたものをエスケープシーケンスといいます。ISO 2022ではこれらを用いて以下のような制御機能を表現します。
- 指示、呼び出し
- 単独の制御機能
- 7単位系におけるC1制御文字
- アナウンサ
- 私用の制御機能
ここではこのうち主なものを紹介します。
4.6.1 ISO 2022のエスケープシーケンス
ここではISO 2022のエスケープシーケンスの一般形について述べます。ISO 2022で規定されるエスケープシーケンスは、以下のような形をしています。
<ESC> <0個以上の中間文字...> <終端文字>
中間文字とは0x20〜0x2Fの範囲の符号であり、終端文字とは0x30〜0x7Eの範囲の符号です。
なお、エスケープシーケンスを構成する中間文字や終端文字は単なる符号であり、特定の文字集合の文字を表現するものではありませんが、便宜上 ESC $ B のようにASCII文字を用いて示すことがあります。
4.6.2 図形文字集合の指示
文字集合の指示はエスケープシーケンスによって表現されます。終端文字Ftは指示すべき文字集合を表します。
ESC ( Ft
ESC ) Ft
ESC * Ft
ESC + Ft
ESC - Ft
ESC . Ft
ESC / Ft
ESC $ Ft
ESC $ ( Ft
ESC $ ) Ft
ESC $ * Ft
ESC $ + Ft
ESC $ - Ft
ESC $ . Ft
ESC $ / Ft
|
94文字集合をG0に指示
94文字集合をG1に指示
94文字集合をG2に指示
94文字集合をG3に指示
96文字集合をG1に指示
96文字集合をG2に指示
96文字集合をG3に指示
94n文字集合をG0に指示(注)
94n文字集合をG0に指示
94n文字集合をG1に指示
94n文字集合をG2に指示
94n文字集合をG3に指示
96n文字集合をG1に指示
96n文字集合をG2に指示
96n文字集合をG3に指示
|
|---|
すでに述べたとおり、96文字集合や96n文字集合をG0に指示することはできないことになっています。
終端文字と文字集合の対応は登録制になっており、ECMAという組織が登録簿を管理しています。以下にいくつか例を示します。
- 94文字集合
- @
- ISO 646 IRV
- B
- US ASCII
- H
- スウェーデン名前用文字
- I
- JIS X 0201カタカナ
- J
- JIS X 0201ローマ文字
- 96文字集合
- A
- ISO 8859-1右半分
- 94n文字集合
- @
- JIS X 0208-1978 (旧JIS漢字)
- A
- GB 2312-80 (中国語簡体字)
- B
- JIS X 0208-1983 (新JIS漢字)
- C
- KS C 5601-1987 (韓国語ハングル・漢字)
- D
- JIS X 0212-1990 (補助漢字)
文字集合の区分は中間文字によって識別されるので、終端文字が同一でも中間文字が異なれば異なる文字集合を表すことに注意してください。
JISコードで使用される指示のシーケンスは以下のようになります。
ESC ( B
ESC ( J
ESC $ @
ESC $ B
|
G0にASCIIを指示する
G0にJIS X 0201ローマ文字を指示する
G0にJIS X 0208-1978を指示する
G0にJIS X 0208-1983を指示する
|
|---|
4.6.3 呼び出しの制御機能など
呼び出しの制御機能の表現は、C0制御文字・C1制御文字・単独の制御機能と多岐にわたっています。単独の制御機能とは、制御文字集合に含まれない制御機能をエスケープシーケンス ESC 0x60〜0x7E で表現するものです。
| 制御機能 | 符号 | 符号の区分 |
SI/LS0
SO/LS1
LS2
LS3
|
0x0F
0x0E
ESC 0x6E
ESC 0x6F
|
C0制御文字
C0制御文字
単独の制御機能
単独の制御機能
|
|---|
LS1R
LS2R
LS3R
|
ESC 0x7E
ESC 0x7D
ESC 0x7C
|
単独の制御機能
単独の制御機能
単独の制御機能
|
|---|
SS2
SS3
|
0x8E
0x8F
|
C1制御文字
C1制御文字
|
|---|
ところで、SS2/SS3がC1制御文字で表現されていますが、これでは7単位系でSS2/SS3が表現できませんね。実は、7単位系でもC1制御文字を表現する方法があるのです。7単位系でC1制御文字を表現するには、C1領域0x80〜0x9Fの代わりにエスケープシーケンス ESC 0x40〜0x5F を使うことになっています。したがって、7単位系のSS2/SS3は以下のようになります。
SS2
SS3
|
ESC 0x4E
ESC 0x4F
|
C1制御文字
C1制御文字
|
|---|
4.7 ISO 2022の運用
以上、ISO 2022の主要部分をみてきました。これだけでもISO 2022が非常に複雑で多様な規格であることがわかってもらえたと思います。このような複雑な規格のフルセットを実装・運用することは現実的てはありません。むしろ、ニーズに応じて適切なサブセットを定めて運用するのが現実的でしょう。
指示や呼び出しは、情報交換当事者同士の合意があれば省略できることになっています。たとえば、多くとも4個の文字集合で足りるようなシステムでは、使用する文字集合をあらかじめG0〜G3に指示してあることにすれば、呼び出しだけで文字集合を切り換えることができます。8単位系で文字集合が2個までであれば、呼び出しすら必要ありません。一方、多くの文字集合を必要とするシステムでは、呼び出しを固定して指示を切り換えるのが適切でしょう。
このように、とくに図形文字集合の扱いにおいてさまざまなサブセットを構成できるようになっているため、全体としてはおおげさとも思えるほどの規模の規格になっているといえます。
第5章 ISO 2022の実例
この章では、ISO 2022の実例について解説します。
5.1 EUC
EUCはISO 2022に準拠したエンコーディング法です。日本語EUCを例にとって説明します。
- G0にASCII(またはJIS X 0201 ローマ文字)を指示
- G1にJIS X 0208 漢字を指示
- G2にJIS X 0201 カタカナを指示
- G3にJIS X 0212 補助漢字を指示
- G0をGLに、G1をGRに呼び出す
- G2とG3はシングルシフトで使用
- エスケープシーケンス・ロッキングシフトは使わない
EUCではX 0208は第1バイトと第2バイトのMSBが1になりますが、これは単にASCIIと区別するために適当にそうしたのではなく、ISO 2022の枠組みに沿って符号化した結果というわけです。カタカナや補助漢字に付く0x8E/0x8Fのプレフィクスも、ISO 2022のシングルシフトに由来しています。
EUCの一般的な構成として、ASCII(またはISO 646)を含めて4つまでの文字集合を扱うことができます。これらはG0〜G3に指示されています。特に、G0にはASCII(ISO 646)、G1にはその言語でもっともよく使う文字集合(ASCII以外)が指示されており、これらはそれぞれGLとGRに呼び出されています。指示および呼び出しは固定されており、エスケープシーケンスやロッキングシフトで変更されることはありません。さらに、補助的に用いる文字集合がG2とG3に指示されており、これらはシングルシフトによって呼び出されます。指示・呼び出しが固定なので、文字列を解釈または生成する際、現在どの文字集合が指示されているかといったような「状態」情報を保持する必要がない(stateless, modeless)ことが大きな特徴です。
なお、通常EUCと呼んでいるものは、正確には情報交換用のEUC packed formatという形式で、文字集合によって1文字のバイト数が変化します。EUCには内部処理用のEUC 2-byte complete formatと呼ばれる形式もあり、これは1バイト文字も2バイト文字もすべて2バイトで表現し、ISO 2022非準拠です。
5.2 JISエンコーディング (JUNETコード、ISO-2022-JP)
JIS(漢字)コードという俗称は、次の二つの意味で使われています。
- JIS X 0208をGLに呼び出した状態でのビット組み合わせ。
- (1)をASCIIなどと共存させるために、ISO 2022準拠の指示のエスケープシーケンスなどを用いるエンコーディング法。
(2)は第1章で説明したJISコードです。今後は(2)をJISエンコーディングと呼ぶことにします。これは典型的なISO 2022準拠のエンコーディング法です。
- G0にJIS X 0201 ローマ文字(またはASCII)を指示
- G1にJIS X 0201 カタカナを指示
- G0をGLに呼び出す
- JIS X 0208漢字(および他の文字集合)はG0に指示して使用
(場合によってはJIS X 0201 カタカナもG0に指示)
- 7ビット環境ではG1はGLに呼び出して使用することが多い
- シングルシフトは使わない
とくに、JISエンコーディングの7ビット版は、日本のインターネットの母体となったJUNETというネットワークにおいて、日本語メッセージ(メール、ニュース)の交換のために使われ、現在に至っています。そのため、時にJUNETコード(Muleの*junet*)とも呼ばれます。また、ISO-2022-JPという名前でRFC 1468に定義されています。
JISエンコーディングの特長は、7ビット環境でも使えることだけでなく、サポートする文字集合をいくらでも増やせること(使いたい集合をG0に指示するだけでよい)です。ISO-2022-JPではASCII・JIS Roman・X 0208(旧/新)だけに限定していますが、これの拡張であるISO-2022-JP-2 (RFC 1554)では、カタカナ・補助漢字や中国・韓国のコードも追加されています。また、ISO 8859もG2に指示して使えることになっています。
このエンコーディング法を「JIS」と呼ぶのは、いくばくかの違和感を禁じえません。というのも、たしかにJIS X 0202(ISO 2022)から構成可能ですが、このエンコーディング法そのものがJIS規格として規定されているわけではないからです。JISエンコーディングとは「必要とする文字集合を随時G0に指示する」という原則からなる不文律のようなものといっていいでしょう。
5.3 シフトJIS
シフトJISは言うまでもなくISO 2022非準拠です。シフトJISの欠点は、すべてこの点に集約されます。第1章でいくつか具体的な欠点をあげましたが、それらはすべて「ISO 2022に準拠していない」という致命的な欠点の系にすぎません。たしかにシフトJISは巧妙に設計されており、日本語処理の黎明期においてカタカナから漢字への円滑な移行を促した役割は評価すべきですが、アドホックな業界標準としての拡張性のなさはいかんともしがたく、今後の国際化・多言語処理の流れに対応できるものではありません。
5.4 ISO 8859、JIS X 0201など
ISO 8859やJIS X 0201などは、それだけで完結した8ビットコードの規格ですが、ASCII(ISO 646)ともう一つの追加文字集合をISO 2022によって組み合わせたものとみることもできます。X 0201については上記のJISエンコーディングの説明でカバーしましたが、ISO 8859については次のようになります。
- G0にASCIIを指示
- G1にISO 8859-x 右半分を指示
- G0をGLに呼び出す
- G1をGRに呼び出す
- エスケープシーケンス・シフト機能は使わない
これを拡張し、G0/G1に各種文字集合を呼び出せるようにした多言語エンコーディング法が、X11R5の国際化機能で採用されました。Compound Text (Muleの*ctext*)と呼ばれます。
5.5 C1制御文字
C0の制御文字集合はいくつかありますが、普通に使われているのはISO 646(ASCII)のそれでしょう。これはいまさら説明するまでもなく、みなさんがいつも使っているものです。それに比べて、C1の制御文字というのはなじみが薄い気がします。SS2 (0x8E)とSS3 (0x8F)はISO 2022で出てきましたが、これ以外で広く使われているものがあるのでしょうか?
実は、あるのです。MS-DOSやxtermで「画面制御用ANSIエスケープシーケンス」と呼ばれているものです。これは、ISO 6429 (ANSI X3.64, JIS X 0211)に規定されているC1集合に準拠しています。ISO 2022の説明で、「C1集合の制御文字(0x80〜0x9F)をESC 0x40〜0x5Fで表現することができる」というのがありましたね。ANSIエスケープシーケンスというのは、ANSI X3.64のC1集合をエスケープシーケンスで表現したものだったのです。
例えば、この規格の0x85に、復帰改行を行うNEL(next line)という制御文字があります。これをエスケープシーケンスで表現するとESC 0x45、つまりESC Eとなります。DOSのマニュアルなどでESC Eを確認してみてください。
また、同じく0x9BにはCSI(control sequence introducer)というのがあります。これはESC 0x5B、つまりESC [となります。ESC [といえば、画面消去・カーソル移動・属性変更など、さまざまなエスケープシーケンスのプレフィクスですね。CSIで始まるこれらのシーケンスは、制御シーケンス(control sequence)と呼ばれています。制御シーケンスは終端文字によってさまざまな機能があり、パラメータをとるものもありますが、これらはすべてISO 6429で規定されています。
第6章 中国語・韓国語の文字コード
この章では、日本語以外に2バイト文字を用いる、中国語・韓国語の文字コード体系について解説します。
6.1 GB 2312
中国本土の国家規格はGB(国家標準)といい、2バイト文字コードの規格も簡体字・繁体字それぞれにいくつか定められています。そのうち最もよく使われるのが、GB 2312という簡体字の規格です。構成はJIS X 0208とよく似ており、次のような特徴をもちます。
- ISO 2022準拠の2バイトコード
- 漢字だけでなく英数字や仮名を含む
- 漢字は第1級漢字(読みの順)と第2級漢字(部首順)に分かれる
実際にはGB 2312はGRに呼び出されてEUCとして使われるケースが多いようです。ちょうど日本語EUCのG0・G1と同じような形になります。
ただし、インターネットでは8ビットデータの通過が必ずしも保証されませんので、alt.chinese.textではHz(Hanzi=漢字)とよばれる独自の7ビットエンコーディングを用いています。Hzでは、GB 2312漢字の開始シーケンスとして~{を、ASCIIの開始シーケンスとして~}を使います。
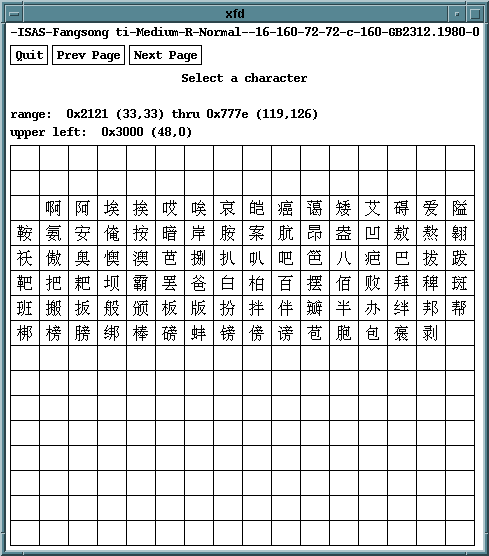
GB 2312
6.2 Big-5とCNS 11643
台湾の有力メーカー5社が中心となって策定したのがBig-5と呼ばれるコードです。メーカーによって独自拡張がありますが、基本的な部分は、第1バイトが0xA1〜0xF9、第2バイトが0x40〜0x7E、0xA1〜0xFEとなっており、設計思想はシフトJISと似ています(もちろんISO 2022非準拠)。ただしコード空間は広くなっており、約13,000字もの文字を収容しています(漢字は繁体字で総画数順)。
シフトJISと本質的に違うのは、シフトJISがJIS X 0208を元にしたエンコーディング法であるのに対して、Big-5は文字集合とエンコーディングが一体となっている点、および、C1制御文字のコードを避けているのでISO 2022との親和性が比較的良い点です。Big-5は台湾や香港のPCで広く使われています。また、alt.chinese.text.big5など一部のニュースグループでも使われています。
逆に、Big-5をもとに台湾の国家規格が作られました。CNS 11643といいます。これはISO 2022準拠の2バイトコード7個からなる膨大な規模の規格です。それぞれを「字面」と呼び、第1・第2字面にBig-5の文字を収容し、第3〜第7字面はそれ以外の特殊な漢字を収容しています。第1・第2字面の配列は基本的にBig-5を踏襲していますが、Big-5の漢字配列の誤りを正しているため、順序は微妙に違います。また、後ろの方の字面になると、まるで書き間違いのような面妖な字が延々と並んで奇観を呈しています。CNS 11643は政府機関などを中心に使われているそうです。ISO 2022準拠のため、EUCを構成することができ、ワークステーションなどへの採用も進んでいると聞きます。
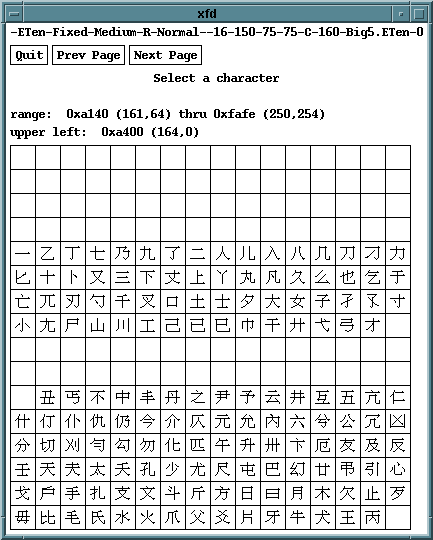
Big-5
6.3 KS C 5601
韓国にもJISやGB同様、ISO 2022準拠の2バイトコードの規格があります。そのうち、JIS X 0208やGB 2312のように最もよく使われるのがKS C 5601です。これは英数字や仮名の他、ハングル2350字、漢字(繁体字)約4000字が含まれています。
ハングルという文字は、子音字母と母音字母の組み合わせによって1文字を構成します。具体的には、初声(子音19種)+中声(母音21種)、または初声+中声+終声(子音27種)という構造になっていて、計算上は19*21*(27+1)=11172字存在します。KS C 5601には、そのうちよく使われるものだけが入っています。また、漢字は読みの順に並んでいます。一部の漢字は複数の読みを持ちますが、これらがそれぞれの読みの所に重複して収録されているのが大きな特徴です。
KS C 5601は、通常はGRに呼び出して韓国語EUCの形で使います。ただし、インターネットでは7ビットでなくてはいけませんので、ISO-2022-KRという7ビットのエンコーディング法(ISO-2022-JPにちょっと近い)で使います。
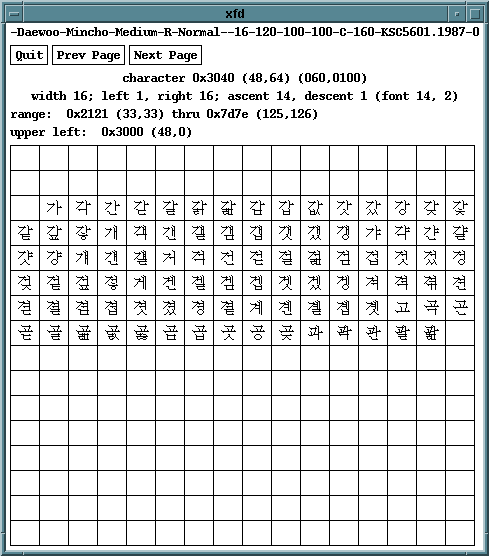
KS C 5601
6.4 組合せ型ハングルコード
ハングルの符号化法には2通りあります。1つは、KS C 5601のように、子音と母音を組み合わせてできた形に対して符号を割り当てるもので、完成型といいます。一方、ハングルの構成原理にのっとって、1文字分のビット(通常16ビット)を3つの部分にわけ、それぞれが初声・中声・終声を表すという方法があります。これは組合せ型といいます。
組合せ型コードはMS-DOSで使われていて、実装したメーカーにより何種類かありますが、ここではKS C 5601の付録に収録されたものについて解説します。初声・中声・終声はそれぞれ5ビットで表せるので、これに識別用の1ビットを加えて16ビットとします。つまり、バイトのMSBが1であればハングルコードとみなし、次のバイトと合わせて15ビットでハングル1字を表します。中声の5ビットがバイト境界にまたがっていたりするので、第2バイトにいろいろとまずいコードが現れそうな気がしますが、これが実に巧妙にできていて、C0/C1制御文字や空白のコードは現れないようになっています。さすがにGLの図形文字のコードと重なるのは避けられず、そのためISO 2022にも非準拠ですが、Big-5同様C1のコードを避けているのでISO 2022との親和性はよくなっています。
第7章 ISO 10646とUnicode
この章は、最近何かと話題のISO 10646とUnicodeの話です。
7.1 ISO 10646成立の経緯
ISOでは、全世界の主要な文字を含んだ単一の文字集合ISO 10646の策定作業に着手しました。一方、国際市場を重視し始めたアメリカの有力コンピュータ企業は、同様の目的で、しかし10646とは全く異なるUnicode(Ver.1.0)という文字集合を策定しました。
ISO 10646は規格原案(DIS 10646 第1版)が投票にかけられましたが、10646とUnicodeの二者並立を嫌う意見により否決されました。そこで、Unicodeの修正案(Ver.1.1)がDIS 10646 第2版として投票にかけられ、ISO 10646-1として成立しました。
その後、ISO 10646-1はJIS X 0221としてJIS規格にもなりました。
7.2 UCSの構造と特徴
ISO 10646はUCS(Universal Character Set, 万国文字集合)と名付けられています。UCSは1文字2バイトの形式(UCS-2)と4バイト(31ビット)の形式(UCS-4)があります。UCS-4の4バイトの値はそれぞれ群(group)、面(plane)、区(row)、点(cell)と呼ばれます。256の点と256の区で表される65536個のコードが1つの面を構成し、256の面で1つの群を構成し、128の群でUCS-4の全体を構成します(群のMSBは未使用)。UCS-4の最初の面、つまり群00の面00をBMP(Basic Multilingual Plane、基本多言語面)と呼びます。現在、BMP以外の面には文字は定義されていません。また、群00面0xE0〜0xFFと群0x60〜0x7Fは私用のために予約されています。
BMPのコードを2バイトで表現したものがUCS-2であり、Unicodeはこれとほぼ同じものです。
BMPは以下のように大別されます。
| A-zone | 0x0000〜0x4DFF
漢字以外の文字・記号
制御文字、アルファベット、各種記号、ハングル、仮名など
|
|---|
| I-zone | 0x4E00〜0x9FFF
漢字 |
|---|
| O-zone | 0xA000〜0xDFFF
拡張用予約領域 |
|---|
| R-zone | 0xE000〜0xFFFD
私用予約領域、互換用文字など |
|---|
A-zoneに含まれている主な文字は次の通りです。
ラテン文字、発音記号、ギリシア文字、キリル文字、アルメニア文字、
ヘブライ文字、アラビア文字、インド諸文字、タイ文字、ラオス文字、
グルジア文字、ハングル、各種記号、罫線、仮名
A-zoneの最初の256文字(0x0000〜0x00FF)はISO 8859-1 (Latin-1)と互換になっています。したがって、最初の128文字(0x0000〜0x007F)はASCIIと互換になっています。
A-zoneには、結合文字(combining character)と呼ばれる文字が含まれています。これは、アルファベットのアクセント記号や仮名の濁点のように、他の文字に付加する記号類のことです。たとえば、「a-ウムラウト」を表すには、「a」のコードの次にウムラウトのコードを置きます。ただし、結合文字を使うと1文字のコード長が可変になってしまって扱いにくいので、よく使われる形については合成済み(precomposed)のコードが用意されており、ほとんどの場合は単一のコードで表現できます。ハングルについても、組合せ型コードと完成型コードが用意されています。組合せ型コードでは1文字4バイトまたは6バイトとなります。
I-zoneには、中国・日本・韓国(CJK)の漢字を統合した約21000字が含まれています。基となった主な文字集合は、中国のGB 2312、台湾のBig-5、日本のJIS X 0208とJIS X 0212、韓国のKS C 5601です。これら各国間では、同じ概念・起源の漢字でも、歴史的・文化的理由により微妙に形が違っている(点画の向きや長さなど)ものが多数ありますが、UCSではそれらを同一の文字とみなし「統合」しています。ただし、基となった集合で区別されている文字は、互換性のためにUCSでも区別されています。
R-zoneは特殊用途の領域であり、アラビア文字の変化形や、既存文字集合との互換性を保つための文字などが含まれています。例えば、シフトJISのテキストには、カタカナや英数字を表現するのにJIS X 0201(いわゆる半角)とJIS X 0208(いわゆる全角)の2通りのコードがあります。これをUCSに変換する際、半角カタカナと全角カタカナを同じコードに変換してしまうと、それをシフトJISに逆変換したとき、元のテキストと異なってしまいます。これを避けるため、A-zoneの本来のカタカナとは別に、R-zoneに「半角カタカナ」が用意してあります。同様に「全角英数字」も用意されています。その他、KS C 5601などで重複して収録されている漢字についても、重複分が用意されており、可逆な変換が可能となっています。このことからわかるように、UCSは、既存の(単一の)文字集合/エンコーディング法との互換性に最大限の留意を払っています。
ISO 10646には、結合文字や組合せ型ハングルの使用を認めるかどうかによって、実装水準という概念が定義されています。
| 実装水準1 | すべて使用不可 |
|---|
| 実装水準2 | 一部の結合文字(主にヨーロッパ諸語)と組合せ型ハングルの使用不可 |
|---|
| 実装水準3 | すべて使用可 |
|---|
Unicodeは実装水準3です。
また、UCSのすべてを実装するのは困難な場合が多いので、その中から必要な文字だけを取り出したサブセットの使用(profiling)を認めています。
7.3 UTF
既存のテキストデータ伝送路は、ISO 2022に準拠した文字データを伝達することを前提にしていますので、そこにUCSのデータをそのまま通すと、制御文字などと誤認されたりして問題が生じます。そのため、UCSに適当なエンコーディングを施して安全に通すことが考えられています。このエンコーディング法はいくつかあり、総称してUTF (UCS Transfer Format)と呼ばれています。これらは、UCSのASCII相当部分(0x0000〜0x007F)は通常の1バイトのASCIIに変換し、それ以外のコードをそれぞれの方法でエンコードします。したがって、ASCIIテキストの中にUCS(の非ASCII文字)を埋め込む方法とみることもできます。
7.3.1 UTF-1
ISO 10646の付録に収録されているUTFです。UCS-2/4の1文字を、1〜5バイトの可変長バイト列にエンコードします。エンコード後のバイトデータは、ISO 2022のGLおよびGR (0x21〜0x7E、0xA1〜0xFE)の範囲になっているため、ISO 2022を前提とした伝送路を安全に通過することができます。エンコードには除算を使います。
UTF-1は、通信や外部記憶などで用いる情報交換用エンコーディング法として設計されましたが、UTF-8という強力な対抗馬が登場したため、実際に広く使われるようになるかどうかは疑問視されています。
7.3.2 UTF-8 (UTF-2, UTF-FSS)
既存のシステムの多くは、ASCII図形文字の一部の文字を特殊文字(区切り文字、エスケープ文字、引用符など)として使っています。このようなシステムにはUTF-1は適しません。UTF-1は、GLとGRの領域をフルに使っているため、エンコード後のデータの第2バイト以降にもGLに相当するコードが現れ、これがASCIIの特殊文字と誤認されて誤動作するおそれがあるからです(シフトJISの第2バイトに0x5Cがあるとバックスラッシュと誤認される問題と似ています)。この点を改善したのがUTF-8です。
UTF-8は、UTF-1同様、UCS-2/4の1文字を、1〜6バイトの可変長バイト列にエンコードします。ただし、UCSの非ASCII文字はGR相当のコード(0xA0〜0xFF)のみを使ってエンコードします。これにより、上記のようなシステムでも、ASCII以外のコードがASCIIと誤認されるおそれはなくなります。また、UTF-8はエンコード/デコードがビットシフトだけで行えるので、効率の面でもUTF-1より有利です。
UTF-8は別名をUTF-2、あるいはUTF-FSS(File System Safe)といいます。FSSという名前は、ファイル名に使ってもパス名の区切り文字(UNIXではスラッシュ)と誤認されたりしない、というところからきています。UTF-8はX/Openやベル研究所によって支持されており、近いうちに10646に収録されてUTF-1にとってかわるだろうというのが大方の予想です。
7.3.3 UTF-7
UTF-1やUTF-8は8ビットの伝送路を前提としていますが、インターネットではいまだに7ビットしか通さない通信路も珍しくありません。また、メールのヘッダ部などでは、ASCII図形文字の使用すら制限されていることがあります。そのような状況でもUCSをエンコードするために考案されたのがUTF-7です。
UTF-7は、MIMEのBase64エンコーディングやuuencodeと類似の方法によって、UCSの非ASCII文字をASCII図形文字にエンコードします。エンコードされた非ASCII部分の前には+を、後ろには-を置くことによって、「地」のASCIIテキストと区別します。
UTF-7はもともと上記のような制限の強い状況で使うためのものであり、広範囲に使われることを目的としたUTF-1やUTF-8とは性格が異なります。
7.3.4 UTF-16
これは、UTFと名付けられてはいますが、目的も内容も他のUTFとは全く異なっています。他のUTFはASCIIテキストにUCSを混ぜるためのものですが、UTF-16はUCS-2のテキストにUCS-4(の一部)を埋め込むためのものです。したがって、他のUTFと併用することもできます。
UTF-16では、UCS-4のうちBMPの次の16面(総文字数1メガ)のコードを、O-zoneのコード2個に変換してUCS-2のテキストに埋め込みます。これにより、UCS-2で表現可能な文字数を大幅に増やすことができます。
しかし一方で、1文字2バイト固定の原則の例外を増やすことになりますし、何よりUCS-4がBMP以外まだ何も決まっていない現状ではやや先走りの感は免れません。BMP(UCS-2)はコード空間が狭い、という批判をかわすための苦肉の策という気もします。
[目次へ]
[email protected]