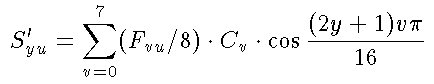
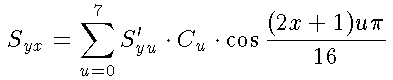
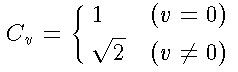
jpeg ローダーを作ろうと決めたのは、東京BBSでしゅいらさんや ARGON さんが小さい jpeg ローダーを作っていて、実は jpeg は簡単なのかなと 思ったからですが、その他にも、去年の駒祭のころにICHI君が MATE 用の jpeg ローダーを作っていて、256色でも結構見られるんだなあと思ったこととか、 ぼくが MATE を買って256色モードが使えるようになったこともあります。 あと、IMAGEPAQについてきた jpeg ローダーがかなり高速で、もえ〜だったと いうのもあります。
というわけで、これから何回かに分けて、jpeg ローダーの作り方を書こうと思います。 jpeg の表示には、ハフマン符号の復号、IDCT、RGBへの変換、減色が必要ですが、 まず1回目は、一番時間がかかると思われる、IDCT(逆離散コサイン変換)について 書こうと思います。
S'yu と Syx の式はほとんど同じなので、後者だけ考えます。
三角関数を、
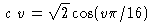 とすると、Syx は
次のように表せます。
とすると、Syx は
次のように表せます。
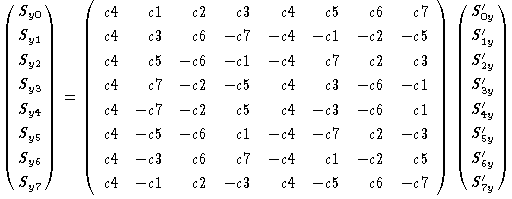
よって、この式のまま計算すると64回の掛け算が必要となります。そこで、この式を 変形して計算を簡単にしたいわけです。
まず、c4=1 ですから、ここでは掛け算はいりません。また、この行列に 現れる係数は、c1,c2,c3,c5,c6,c7 の6種類しかないので、 掛け算用のテーブルを作ることもできます。 次に、上の行列を偶数列と奇数列に分けると、次のようになります。
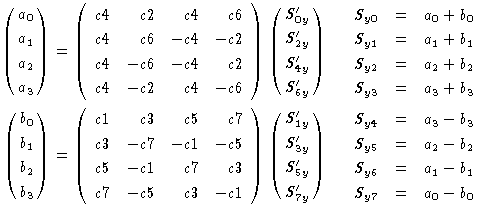
つまり、もとの行列の上半分と下半分が全く同じか符号が違うだけなので、 一度行った計算が他のところに使えるようになり、掛け算を減らすことが できるわけです。偶数列に対しては、同じように4で割った余りで列を分ければ さらに掛け算が減ります。奇数列も同じようなことができますが、掛ける数の種類が 増えてしまうのでやめておきます。
以上のようにすると、Sy0, …, Sy7 の計算は20回の掛け算でできることに なります。え? 掛け算は11回ですむはずだって? うーむ。まあいいでしょう(笑)。
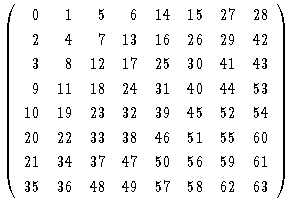
つかれた(笑)。つまり、F00,F01,F10,F20, F11,F20,… という順番で入っています。そして、終了の 符号のあとはすべて 0 になっています。たとえば 35 (F70) で終わりだと すると、行列の右下半分はすべて 0 になっているわけです。よって、データの数に よって計算するルーチンを分ければいいのです。
例えば、F00 だけが 0 でないとすると、 S'00 = S'01 = S'02 = S'03 = S'04 = S'05 = S'06 = S'07 = F00 となり、ほかの S'yu は 0 になります。jpeg で圧縮率が良い絵の場合、 この周波数のデータが 3 つしかないというところがわりとあります。ですから データによってルーチンを分ける方法はかなり有効のようです。
さて、ぼくのプログラムがどうなっているかです。 まず Fvu から S'yu を計算する部分ですが、 64通りのルーチンを作ると なんかプログラムがでかくなりそうでいやなので (なんか昔と考え方が違うな)、 行に関して上から何番目まで 0 でないデータが入っているかによって8通りの ルーチンを作り、それを8回呼ぶようにしました。例えば、0 から 5 まで データが入っている場合は、1 列目が 3 個、2 列目が 2 個、3 列目が 1 個なので それぞれに対応するルーチンを呼ぶようになっています。
S'yu から Syx を計算する部分は、上とは違って各列ごとに 0 でないデータの数が違うなんてことはないのですが、 ある行より下は全て 0 になっていることがあります。上の 0 から 5 までの例では、 Fvu が 3 列目までしかないので、S'yu は 3 行目までしかないと いうことになります。よってこちらは 64 通りではなく 8 通りに分けるわけです。 なお、こうすることで S'yu に現れる 0 をメモリに書かなくてすむこと にも注意してください。ついでに、F00 だけが 0 でないばあいは Syx は 64個全てが F00/8 と等しくなるので、この場合だけはサブルーチンを 8+1 回呼ぶようにはせずに専用のルーチンにしています。
even
de05:
push offset idctsub22
push offset idctsub10
push offset idctsub11
jmp idctsub12
even
idctsub22:
assume ds:_tbl,es:_tbl,ss:_dat
mov di,blk
mov si,offset dcttmp
mov di,dctob[di]
mov k,8
id221: mov bx,[si+2*16]
add bx,bx
mov cx,[si+0*16]
mov ax,dctmul2[bx] ; c2
mov bp,dctmul6[bx] ; c6
mov bx,[si+1*16]
add bx,bx
add cx,ax
mov dx,dctmul1[bx]
add cx,dx
mov [di+0*2],cx
sub cx,dx
sub cx,dx
mov [di+7*2],cx
add cx,dx
sub cx,ax
sub cx,ax
mov dx,dctmul7[bx]
add cx,dx
mov [di+3*2],cx
sub cx,dx
sub cx,dx
mov [di+4*2],cx
add cx,dx
add cx,ax
add cx,bp
mov dx,dctmul3[bx]
add cx,dx
mov [di+1*2],cx
sub cx,dx
sub cx,dx
mov [di+6*2],cx
add cx,dx
sub cx,bp
sub cx,bp
mov dx,dctmul5[bx]
add cx,dx
mov [di+2*2],cx
sub cx,dx
sub cx,dx
mov [di+5*2],cx
add si,2
add di,16
dec k
jnz short id221
ret
[email protected] までお願いします。
また、ぼくの作ったプログラムは http://naomi.is.s.u-tokyo.ac.jp/~sada/
にありますので使ってみてください。
[総目次へ]
[email protected]